Bu günlerde büyük dil modelleri (LLMS), 1996’dan beri var olmalarına rağmen devrimci bir şey değil (Joseph Weizenbaum tarafından geliştirilen Eliza, konuşmada bir psikoterapist simüle ediyor). İnsanlara her zaman bu sinir ağı destekli harikaların, şaşırtıcı akıcılıkla insan dilini nasıl anlayabileceğini ve üretebileceğini ve inanılmaz olasılıklara kapıları nasıl açabileceğini şaşırtır. Ancak bu güç bir bedeli geliyor. Kritik bir kavşakla karşı karşıya olduğumuza inanıyorum: Güvenlik risklerini kafa kafaya ele almadıkça, LLM’lerin potansiyeli güvenlik açıkları tarafından gölgede bırakılabilir. Çoğu LLM’nin günlük yaşamda gördüğümüz kullanıcı istemlerine nasıl tepki verdiğini anlamakla başlayalım:
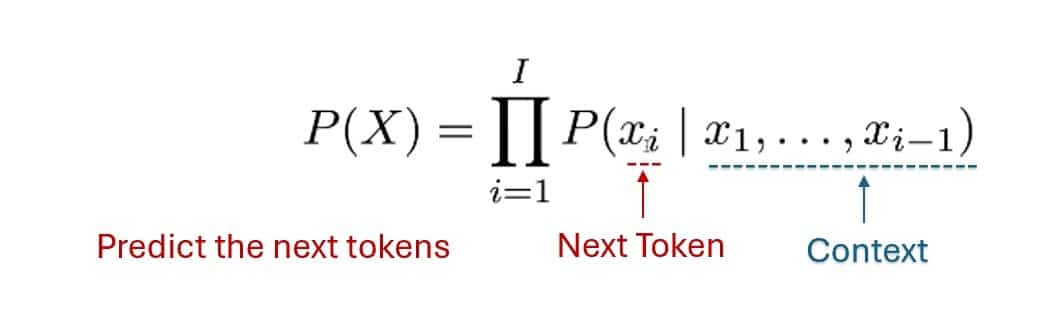
| Olasılıksal dil modellemesini açıklayan şekil |
Bu modellerin nasıl inşa edildiğini parçalayalım. İlk olarak, bilgi dağlarının modele beslendiği veri hazırlığı gelir. Huggingface’den Thomas Wolf’un belirttiği gibi, veriler kalite burada pazarlık edilemez. Her şeyin üzerine inşa edildiği temeldir. Sırada, modelin dilin nüanslarını kavramaya başladığı eğitim öncesi. Ardından, belirli görevler için modeli uzmanlaştıran ince ayar yapıyoruz. Son olarak, insan geri bildirimlerinden (RLHF) takviye öğrenimi, modelin çıktılarına ince ayar yapar ve bunları beklentilerimizle hizalar.
Denetimli öğrenme
- Çocuk elma, muz ve portakal resimlerini gösterir ve onlara her meyvenin adını söylersiniz.
- Daha sonra, yeni bir meyve gösterdiğinizde, çocuk bunu tanımlamak için geçmiş bilgileri kullanır.
Denetimsiz öğrenme
- Çocuğa karışık meyve sepeti veriyorsunuz ama onlara isimleri anlatmayın.
- Çocuk, benzer görünümlü meyveleri birlikte gruplamaya başlar (örneğin, tüm yuvarlaklar, tüm sarı olanlar).
Takviye öğrenimi
- Çocukla bir oyun oynarsınız: Bir meyveyi doğru bir şekilde tanımlarlarsa şeker alırlar; Eğer yanlış yaparlarsa, şeker yok.
- Zamanla, çocuk daha iyi tahminler yaparak ödülleri en üst düzeye çıkarmayı öğrenir.
Ama işte yakalama: her aşama güvenlik açıkları sunar. Eğitim yönteminin kendisi-federasyon yapmayan, federe veya merkezi olmayan-farklı riskleri zorlar. Federasyon olmayan modellerde merkezi veriler? Bilgisayar korsanları için birincil hedef. Federasyonlu eğitim, daha fazla dağıtılırken, veri zehirlenmesine karşı hassastır – birisinin modelin davranışını ustaca bozması için kötü niyetli veriler enjekte ettiğini hayal edin. Ve merkezi olmayan sistemler? Saldırı yüzeyini katlanarak genişletiyorlar.
Tehditler çok yönlü ve sürekli gelişiyor. Bunlardan bazıları, saldırganların modelin çıktılarını çarpıtmak için yozlaşmış veri enjekte ettikleri veri zehirlenmesidir. Sonra model inversiyon saldırıları, modelin öğrendiği değerli bilgileri çalma girişimleri var. Düşmanca saldırılar, modelin tuhaf veya zararlı hatalar yapmasına neden olan ince giriş değişikliklerinin üretilmesini içerir-bir durma işaretini yeşil ışık olarak yanlış yorumlayan kendi kendine giden bir arabayı düşünün. Ayrıca, kötü niyetli istemlerin modeli güvenlik önlemlerini atlamak veya hassas verileri ortaya çıkarmak için manipüle ettiği hızlı enjeksiyonu unutmayın. Son olarak, fikri mülkiyeti tehlikeye atarak, tescilli LLM’leri çalmak için sofistike tekniklerin kullanıldığı model hırsızlığı var.
Bu riskler sadece teorik değil. İnanılmaz derecede ikna edici kimlik avı e -postaları ürettiğini, yanlış bilgilendirme kampanyalarını büyük ölçekte otomatikleştirdiğini veya itibarlara zarar verebilecek veya seçimleri manipüle edebilecek derin dişler oluşturmak için kullanıldığını hayal edin. Kötüye kullanım potansiyeli muazzamdır.
Bu, siber güvenlik profesyonelleri için büyük bir zorluk oluşturuyor. LLM’ler için güçlü bir araç olabilir savunma – Tehdit algılamasını otomatikleştirmek – ancak – ancak kolayca silahlandırılabilirler. Klasik çift kenarlı bir kılıç. İki yönlü bir yaklaşıma ihtiyacımız var: LLM’lerin gücünü iyi kullanırken, aynı zamanda kötüye kullanımlarına karşı sağlam korumalar oluştururken.
Peki, buradan nereye gidiyoruz? Kapsamlı veri veterinerleme, düzenli güvenlik değerlendirmeleri, güvenli eğitim yöntemleri, sağlam anomali tespiti ve önemli bir şekilde etik tasarım ilkelerine ihtiyacımız var. Ancak teknoloji tek başına kesmeyecek. LLMS için daha güvenli bir gelecek yaratmak için birlikte çalışan işbirliğine – geliştiricilere, güvenlik uzmanlarına, politika yapıcılara, etikçilere – ihtiyacımız var.
Yapay zeka tarafından oluşturulan içeriğin gerçeklikten ayırt edilemez olduğu bir dünya hayal edin. Bir politikacının sesi ve yüzü mükemmel bir doğrulukla çoğaltılabilir. Sahte kanıtlar ölçekte üretilebilir. Bilgiye olan güvenimiz hangi noktada çöküyor?
Sonunda, sorumluluğa gelir. Buluşlar, ne kadar çığır açıcı olursa olsun, ne doğal olarak iyi ne de kötüdür. Nükleer teknoloji şehirlere güç verebilir veya onları yok edebilir. İnternet bizi birbirine bağlayabilir veya yanlış bilgilendirebilir. LLM’ler farklı değildir. Etkileri tamamen onları nasıl kullanmayı seçtiğimize bağlıdır. Proaktif olmalıyız, gerçekleşmeden önce riskleri tahmin etmeliyiz ve hafifletmeliyiz. Yapay zekanın geleceği ve belki de çok daha fazlası buna bağlıdır.
Yazar hakkında
 Hrishitva Patel, teknoloji, veri analizi ve sanatsal ifade tutkusu olan özel bir profesyoneldir. Yolculuğu akademik başarıların, profesyonel büyümenin ve yaratıcı keşiflerin bir karışımı oldu.
Hrishitva Patel, teknoloji, veri analizi ve sanatsal ifade tutkusu olan özel bir profesyoneldir. Yolculuğu akademik başarıların, profesyonel büyümenin ve yaratıcı keşiflerin bir karışımı oldu.
Hrishitva akademik arayışlarına SRM Üniversitesi Kattankulathur’da (KTR) başladı ve burada bir B.Tech kazandı ve mühendislikte güçlü bir temel oluşturdu. Daha sonra uzmanlığını SUNY Binghamton’da bilgisayar biliminde bir yüksek lisans tamamlayarak geliştirdi ve burada en yeni teknolojileri ve veri odaklı bilgileri araştırdı.
Şu anda, Hrishitva aktif olarak veri analizi ve makine öğrenimi ile ilgileniyor, becerilerini anlamlı kalıpları ortaya çıkarmak ve karmaşık veri kümelerinden değerli bilgiler çıkarmak için becerilerini uyguluyor. Çalışmaları, gerçek dünya sorunlarını çözmek ve veri odaklı karar almayı geliştirmek için teknolojiyi kaldırmaya odaklanıyor.
Bilgi sistemleri ve iş stratejisi hakkında daha geniş bir anlayış arayan Batı Valileri Üniversitesi’nde MBA yaptı. Bu deneyim, liderlik becerilerini geliştirmesine ve teknoloji ve iş arasındaki kesişme hakkında kapsamlı bir görüş kazanmasına izin verdi. Akademik yolculuğunu ilerleten Hrishitva, Ph.D. San Antonio’daki (UTSA) Texas Üniversitesi’ndeki bilgi sistemlerinde program ve burada gelişen veri ve teknoloji araştırmalarına katkıda bulunmayı hedefliyor.
Akademik ve profesyonel çabalarının ötesinde Hrishitva, resimde teselli ve yaratıcı ifade bulur. Sanat, teknoloji odaklı arayışlarına karşı bir denge görevi görür ve tuval üzerindeki renkli vuruşlarla hayal gücünü ve yaratıcılığı keşfetmesine izin verir.
Hrishitva, veri analizi, teknoloji ve sanat için tutkularını sorunsuz bir şekilde entegre eden yaşam boyu öğrenen bir öğrencinin ruhunu somutlaştırır. Yolculuğu, merak, yenilik ve alanında bir etki yaratma taahhüdü ile gelişmeye devam ediyor.
Hrishitva Patel’e çevrimiçi olarak ulaşılabilir-https://www.linkedin.com/in/hrishitva-patel