
GroK 4, GroK 3’ten büyük bir sıçrama, ancak Gemini 2.5 Pro gibi pazardaki diğer modellere kıyasla ne kadar iyi? Şimdi yeni bağımsız kriterler sayesinde cevaplarımız var.
Kitle kaynaklı AI kıyaslama için açık bir platform olan LMARENA.AI, GROK 4’ün sonuçlarını yayınladı.
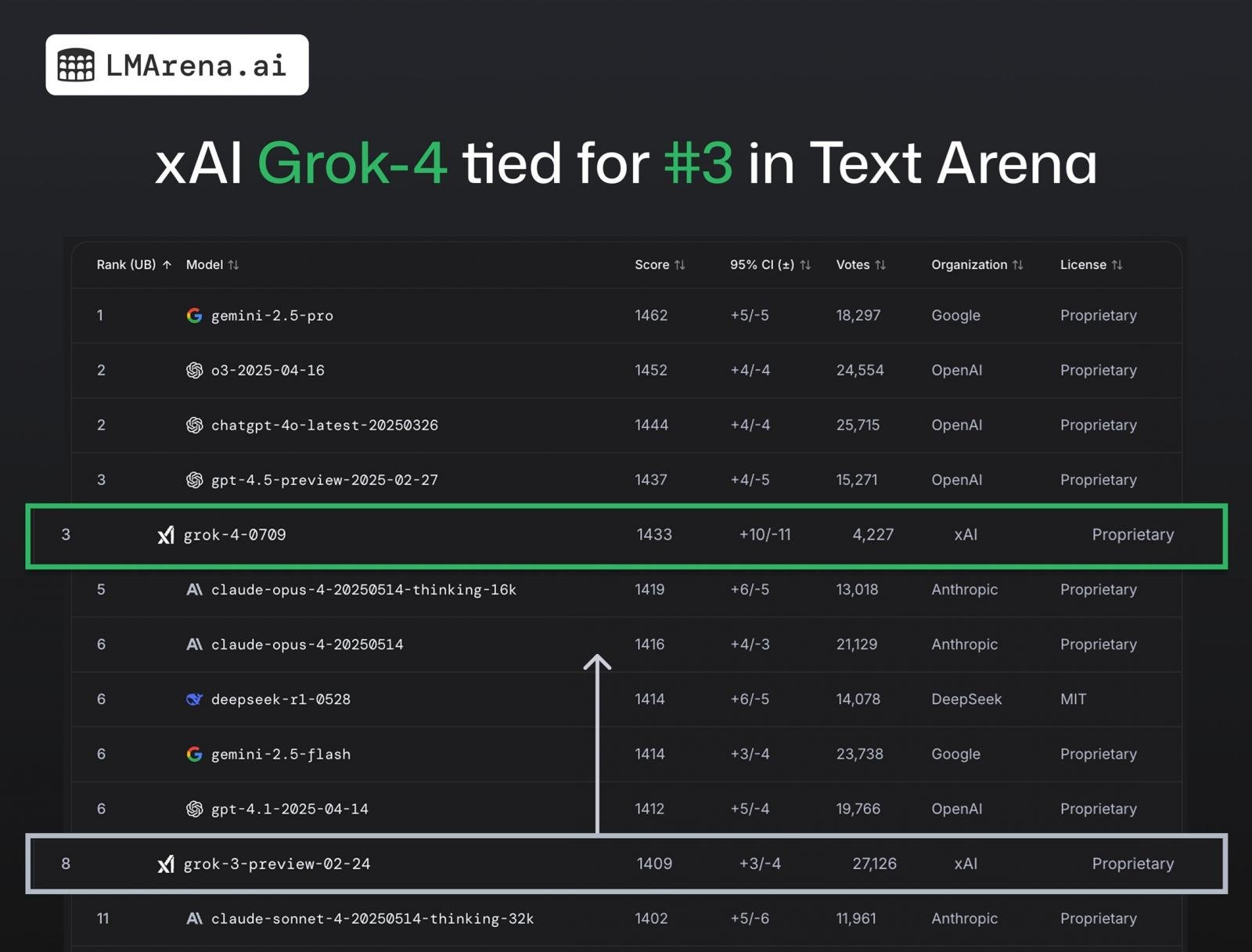
Yaklaşık 4K+ topluluk oyu alan ve metin arenasında genel olarak 3. sırada yer alan GROK 4 API (GROK-4-0709) hakkında konuşuyoruz. Bu, 8. sırada yer alan GroK 3’ten büyük bir sıçrama.
Lmarena’nın testlerine göre, GROK 4 tüm kategorilerde Top-3 puan alır (Matematikte #1, kodlamada #2, sert istemlerde #3).
GroK 4, kodlama, matematik ve yaratıcı yazma gibi alanlar arasında gerçek dünya istemleri ile test edildi ve gerçekten iyi performans gösterdi:
- Matematik: #1
- Kodlama: #2
- Yaratıcı yazı: #2
- Aşağıdaki talimat: #2
- Zor istemler: #3
Bununla birlikte, test edilen modelin GroK 4 ağır değil, GROK 4 olduğunu belirtmek gerekir.
Her ikisi de akıl yürütme modelleri olsa da, Grook 4 Heavy önemli ölçüde daha iyidir.
Sonuçları düşünmek ve karşılaştırmak için birden fazla ajan kullanan GROK 4 Heavy ile sayılar farklı olabilir, ancak GROK 4 Heavy modeli API platformunda henüz mevcut değildir.
Gemini 2.5 Pro ve Claude hala kodlama için en iyi modeller olmaya devam ediyor, ancak Xai Ağustos ayında Grok 4 kodunu kullandığında değişebilir.
GROK 4 kodu kodlama için optimize edilmiştir ve ayrıca Gemini CLI ve Claude koduna benzer bir CLI bekliyoruz.

Bulut saldırıları daha sofistike büyüyor olsa da, saldırganlar hala şaşırtıcı derecede basit tekniklerle başarılı oluyorlar.
Wiz’in binlerce kuruluşta tespitlerinden yararlanan bu rapor, bulut-yüzlü tehdit aktörleri tarafından kullanılan 8 temel tekniği ortaya koymaktadır.