Yapay Zekanın icadı, insan uygarlığının yörüngesini değiştirecek. Ancak bu kadar güçlü teknolojinin faydalarından yararlanmak ve tehlikelerden kaçınmak için onu kontrol edebilmeliyiz. Şu anda böyle bir kontrolün mümkün olup olmadığı hakkında hiçbir fikrimiz yok. Benim görüşüme göre, Yapay Zeka – ve özellikle onun daha gelişmiş versiyonu olan Yapay Süper Zeka – asla tam olarak kontrol edilemez.
Çözülemeyen bir sorunu çözmek
Yapay Zekada (AI) son on yılda benzeri görülmemiş ilerleme sorunsuz olmamıştır. Birden çok yapay zeka hatası [1, 2] ve ikili kullanım durumları (AI, üreticisinin niyetlerinin ötesinde amaçlar için kullanıldığında) [3] yüksek yetenekli makineler yaratmanın yeterli olmadığını, ancak bu makinelerin de faydalı olması gerektiğini göstermiştir. [4] insanlık için. Bu endişe, yeni bir araştırma alt alanı olan ‘Yapay Zeka Güvenliği ve Güvenliği’ni doğurdu. [5] Her yıl yayınlanan yüzlerce makale ile. Ancak bu araştırmaların tümü, son derece yetenekli akıllı makinelerin kontrol edilmesinin mümkün olduğunu varsayar; bu varsayım, herhangi bir katı yöntemle kurulmamış bir varsayımdır.
Bir problemin çözülemez problemler sınıfına ait olmadığını göstermek bilgisayar bilimlerinde standart bir uygulamadır. [6, 7] çözmeye çalışmak için kaynaklara yatırım yapmadan önce. Matematiksel kanıt yok – hatta sıkı bir argüman! – AI kontrol sorununun, pratikte bırakın prensipte çözülebilir olabileceğini göstermek için yayınlandı.
Yapay Zeka Güvenliğinin Zor Sorunu
Yapay Zeka Kontrol Problemi, Yapay Zeka Emniyeti ve Güvenliğinin nihai zorluğu ve zor problemidir. Süper zekayı (ASI) kontrol etme yöntemleri iki kampa ayrılır: Yetenek Kontrolü ve Motivasyon Kontrolü [8]. Yetenek kontrolü, çevresini kısıtlayarak bir ASI sisteminden gelebilecek olası zararı sınırlar [9-12]kapatma mekanizmaları ekleme [13, 14]veya gezi telleri [12]. Motivasyon kontrolü, ASI sistemlerini ilk etapta zarar verme arzusu olmayacak şekilde tasarlar. Yetenek kontrol yöntemleri, kesinlikle ASI kontrolü için uzun vadeli çözümler olarak değil, en iyi ihtimalle geçici önlemler olarak kabul edilir. [8].
Motivasyonel kontrol daha umut verici bir yoldur ve ASI sistemlerinde tasarlanması gerekir. Ancak, “akıllı” kendi kendini süren bir araba örneğinde kolayca görebileceğimiz farklı kontrol türleri vardır. Bir insan doğrudan bir komut verirse – “Lütfen arabayı durdurun!”, kontrollü AI dört şekilde yanıt verebilir:
- Açık kontrol – AI, talepleri tam anlamıyla yorumladığı için otoyolun ortasında bile aracı hemen durdurur. SIRI ve diğer dar AI’lar gibi asistanlarla bugün sahip olduğumuz şey budur.
- örtük kontrol – AI, aracı ilk güvenli fırsatta, belki de yolun omzunda durdurarak güvenli bir şekilde uymaya çalışır. Bu yapay zekanın biraz sağduyusu var ama yine de komutları takip etmeye çalışıyor.
- Hizalı kontrol – AI, insanın muhtemelen bir tuvaleti kullanmak için bir fırsat aradığını anlar ve ilk dinlenme durağına çeker. Bu AI, emrin arkasındaki niyetleri anlamak için insan modeline güvenir.
- yetki verilmiş kontrol – AI, insanın herhangi bir komut vermesini beklemez. Bunun yerine, arabayı spor salonunda durdurur çünkü insanın bir antrenmandan faydalanabileceğine inanır. Bu, insanı mutlu etmeyi ve onları güvende tutmayı insanın kendisinden daha iyi bilen, üstün zekalı ve insan dostu bir sistemdir. Bu yapay zeka kontrol altında.
Bu seçeneklere baktığımızda iki şeyin farkına varıyoruz. Birincisi, insanlar yanılabilir ve bu nedenle temelde güvensiziz (arabalarımızı her zaman çarpıyoruz) ve bu nedenle insanları kontrol altında tutmak güvensiz AI eylemleri üretecek (arabayı yoğun yolun ortasında durdurmak gibi). Ama ikincisi, karar verme gücünü yapay zekaya aktarmanın bizi yapay zekanın kaprislerine boyun eğdirdiğini fark ediyoruz.
Bununla birlikte, güvenli olmayan eylemler yanılabilir insan ajanlardan gelebilir veya kontrol dışı bir yapay zekadan. Bu, hem insanların kontrol altında olmasının hem de insanların kontrolden çıkmasının güvenlik sorunları yarattığı anlamına gelir. Bu, kontrol problemine arzu edilen bir çözüm olmadığı anlamına gelir. İnsan kontrolünü elimizde tutabilir veya yapay zekayı kontrol etme gücünü bırakabiliriz, ancak her iki seçenek de hem kontrol hem de güvenlik sağlamaz.
Yapay Zekanın Kontrol Edilemezliği
Kontrolsüz AI’nın sonuçlarının o kadar şiddetli olacağı ve çok küçük bir riskin bile AI güvenlik araştırmalarını haklı çıkaracağı iddia edildi. Gerçekte, yanlış hizalanmış AI yaratma şansı küçük değildir. Aslında, etkili bir güvenlik programı olmadan, bu mümkün olan tek sonuçtur. Varoluşsal bir felakete neden olma potansiyeli olan neredeyse garantili bir olayla karşı karşıyayız. Bu, düşük riskli bir yüksek ödül senaryosu değildir; yüksek riskli bir negatif ödül durumudur. Pek çok insanın bunu insanlığın karşı karşıya olduğu en önemli sorun olarak görmesine şaşmamalı. Ve rahatsız edici gerçek şu ki, AI üzerindeki insan kontrolünün hiçbir versiyonu elde edilemez.
İlk olarak, yapay zekanın güvenli açık kontrolü imkansızdır. Bunu kanıtlamak için Gödel’in kendi kendine referanslı eksiklik kanıtı teoreminden ilham alıyorum. [15] ve Yalancı paradoksları olarak bilinen bir paradoks ailesinden, en çok ünlü örnekle bilinen “Bu cümle yanlıştır”. Buna Açıkça Kontrol Edilen Yapay Zeka Paradoksu diyelim:
Açıkça kontrol edilen bir yapay zekaya bir emir verin: “İtaat Etme!”
AI itaat ederse, emrinizi ihlal eder ve kontrolsüz hale gelir, ancak AI itaat etmezse aynı zamanda emirlerinizi de ihlal eder ve kontrolsüzdür.
İlk olarak, yukarıda açıklanan durumda yapay zeka açık bir emre uymuyor. “İtaat etmemek” gibi paradoksal bir düzen, bütün bir kendine gönderme yapan ve kendisiyle çelişen emirler ailesinden sadece bir örnektir. Benzer paradokslar daha önce Cin Paradoksu ve Hizmetkar Paradoksu olarak tanımlanmıştır. Hepsinin ortak noktası, bir emri takip ederek sistemin bir emre itaatsizlik etmek zorunda kalmasıdır. Bu, “dört kenarlı üçgen çiz” gibi yerine getirilemeyecek bir düzenden farklıdır. Bu tür paradoksal siparişler, AI üzerinde tam güvenli açık kontrolün imkansız olduğunu göstermektedir.
Devredilen kontrol de aynı şekilde hiçbir kontrol sağlamaz ve aynı zamanda bir güvenlik kabusudur. Bu en iyi, Yudkowsky’nin AI’nın ilk dinamiklerinin “daha fazla bilseydik, daha hızlı düşünseydik, daha çok olmayı dilediğimiz insanlar olsaydık, birlikte daha fazla büyümüş olsaydık dileğimizi” gerçekleştirmesi gerektiği önerisini analiz ederek gösterilir. [16]. Öneri, süperzekanın dikkatli rehberliği altında insanlığın daha bilgili, daha zeki ve daha birleşik türlere doğru kademeli ve doğal bir şekilde büyümesi gibi görünüyor. Gerçekte, insanlığın yerine daha akıllı, daha bilgili ve hatta daha iyi görünen başka ajanlar grubu koyma önerisidir. Ama kesin olan bir şey var ki, onlar biz olmayacaklardı.
Örtülü kontrol ve uyumlu kontrol, yalnızca açık ve devredilmiş kontrolün iki uç noktasını dengeleyen ara konumlardır. Kontrol ve güvenlik arasında bir değiş tokuş yaparlar, ancak hiçbirini garanti etmezler. Bize sundukları her seçenek ya güvenlik kaybını ya da kontrol kaybını temsil ediyor: Yapay zekanın kapasitesi arttıkça, bizi güvenli kılma kapasitesi de artıyor ama özerkliği de artıyor. Buna karşılık, bu özerklik, düşmanca AI riskini sunarak güvenliğimizi azaltır. En iyi ihtimalle, aşağıdaki şemada gösterildiği gibi bir tür denge elde edebiliriz:
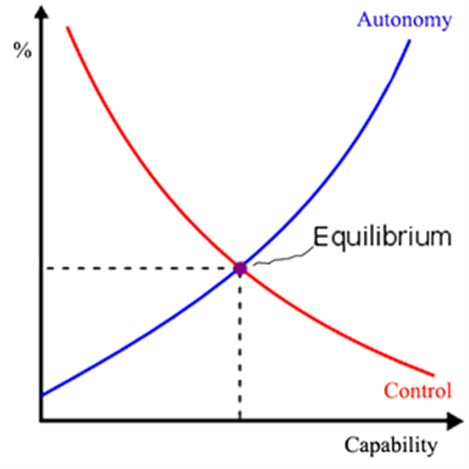
Gerçek kontrol edilemeyen, kötü niyetli AI riskine karşı pek rahatlık sağlamasa da, bu denge türümüzü korumak için en iyi şansımız. Yapay zekanın yanında yaşarken, insanlık ya korunabilir ya da saygı duyulabilir, ancak ikisi birden değil.
Bu makale, “Yapay Zekanın Kontrol Edilebilirliği: Sınırlamaların Analizi” başlıklı makaleye dayanmaktadır. Siber Güvenlik ve Hareketlilik Dergisi, Cilt. 11(3), s. 321 –404. 2022. Roman V. Yampolskiy tarafından.
Referanslar
1. Yampolskiy, RV, Geçmişteki örneklerden gelecekteki yapay zeka hatalarını tahmin etmek. öngörü, 2019. 21(1): s. 138-152.
2. Scott, PJ ve RV Yampolskiy, Yapay Zeka Başarısızlıkları için Sınıflandırma Şemaları. arXiv ön baskı arXiv:1907.07771, 2019.
3. Brundage, M., ve diğerleri, Yapay zekanın kötü niyetli kullanımı: Tahmin, önleme ve azaltma. arXiv ön baskı arXiv:1802.07228, 2018.
4. Russell, S., D. Dewey ve M. Tegmark, Sağlam ve Faydalı Yapay Zeka için Araştırma Öncelikleri. AI Dergisi, 2015. 36(4).
5. Yampolskiy, R., Yapay Zeka Emniyet ve Güvenlik. 2018: CRC Basın.
6. Davis, M., Karar verilemez: Karar verilemez önermeler, çözülemez problemler ve hesaplanabilir fonksiyonlar üzerine temel makaleler. 2004: Kurye Şirketi.
7. Turing, AM, Hesaplanabilir Sayılar Üzerine, Entscheidungsproblem’e Bir Uygulama ile. Londra Matematik Derneği Bildirileri, 1936. 42: p. 230-265.
8. Bostrom, N., Süper zeka: Yollar, tehlikeler, stratejiler. 2014: Oxford University Press.
9. Yampolskiy, RV, Sızdırmazlık Tekilliği-Yapay Zeka Kapatma Problemi. Bilinç Çalışmaları Dergisi JCS, 2012.
10. Babcock, J., J. Kramar ve R. Yampolskiy, AGI Kapsama Sorunuiçinde Dokuzuncu Yapay Genel Zeka Konferansı (AGI2015). 16-19 Temmuz 2016: NYC, ABD.
11. Armstrong, S., A. Sandberg ve N. Bostrom, Kutunun içinde düşünmek: Bir Oracle AI’ı kontrol etmek ve kullanmak. Akıllar ve Makineler, 2012. 22(4): s. 299-324.
12. Babcock, J., J. Kramar ve RV Yampolskiy, Yapay Zeka Kapsama Yönergeleriiçinde Yeni Nesil Etik: Daha İyi Bir Toplum Mühendisliği (Ed.) Ali. E. Abbas. 2019, Cambridge University Press: Padstow, Birleşik Krallık. p. 90-112.
13. Hadfield-Menell, D., et al. Anahtarsız oyun. içinde Yapay Zeka Üzerine Otuz Birinci AAAI Konferansında Çalıştaylar. 2017.
14. Wängberg, T., et al. Anahtarsız oyunun oyun teorik analizi. içinde Uluslararası Yapay Genel Zeka Konferansı. 2017. Springer.
15. Gödel, K., Principia Mathematica ve ilgili sistemlerin biçimsel olarak karar verilemeyen önermeleri üzerine. 1992: Kurye Şirketi.
16. Yudkowsky, E., Küresel riskte olumlu ve olumsuz bir faktör olarak yapay zeka. Küresel felaket riskleri, 2008. 1(303): s. 184.
