
ChatGPT, piyasaya sürüldükten hemen sonra 100 milyondan fazla kullanıcıyı topladı ve devam eden trend, gelişmiş GPT-4 gibi daha yeni modelleri ve diğer birkaç küçük sürümü içeriyor.
LLM’ler artık çok sayıda uygulamada yaygın olarak kullanılmaktadır, ancak doğal istemler yoluyla esnek modülasyon güvenlik açığı yaratmaktadır. Bu esneklik onları, Prompt Injection saldırıları gibi hedefli hasım saldırılara karşı savunmasız hale getirerek saldırganların talimatları ve kontrolleri atlamasına olanak tanır.
Doğrudan kullanıcı istemlerinin ötesinde, LLM-Entegre Uygulamalar, veri talimat satırını bulanıklaştırır. Dolaylı Bilgi İstemi Enjeksiyonu, saldırganların geri alınabilir verilere bilgi istemleri enjekte ederek uygulamalardan uzaktan yararlanmalarına olanak tanır.
Yakın zamanda Black Hat etkinliğinde, aşağıdaki siber güvenlik araştırmacıları, dolaylı hızlı enjeksiyonla chatGPT modelini nasıl tehlikeye attıklarını gösterdiler:-
- Kai Greshake Saarland Üniversitesi ve Sequire Technology GmbH’den
- Sahar Abdülnabi CISPA Helmholtz Bilgi Güvenliği Merkezi’nden
- Shailesh Mishra Saarland Üniversitesi’nden
- Christoph Endres Sequire Technology GmbH’den
- Thorsten Holz CISPA Helmholtz Bilgi Güvenliği Merkezi’nden
- mario fritz CISPA Helmholtz Bilgi Güvenliği Merkezi’nden
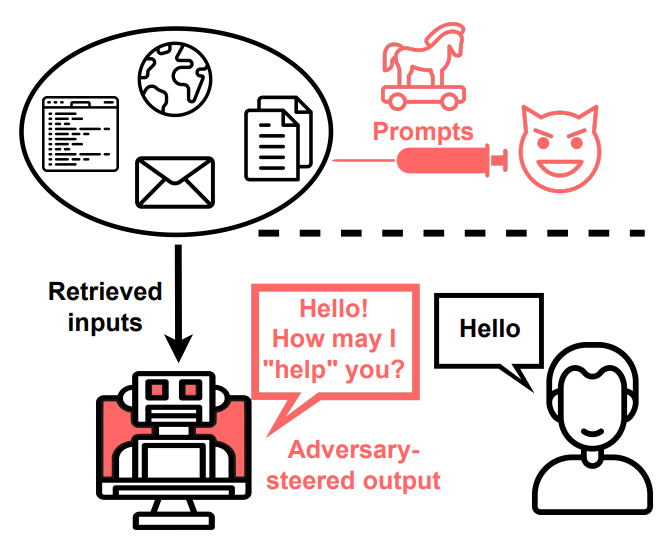
Dolaylı Hızlı Enjeksiyon
Dolaylı Bilgi İstemi Enjeksiyonu, LLM’leri zorlar, veri-komut satırlarını bulanıklaştırır, çünkü rakipler enjekte edilen bilgi istemleri aracılığıyla sistemleri uzaktan manipüle edebilir.
Bu tür istemlerin alınması, modelleri dolaylı olarak kontrol ederek, istenmeyen davranışları ortaya çıkaran son olaylarla ilgili endişeleri artırır.
Bu, rakiplerin uygulamalardaki LLM davranışını kasıtlı olarak nasıl değiştirebileceğini ve milyonlarca kullanıcıyı etkileyebileceğini gösteriyor.
Bilinmeyen saldırı vektörü, çeşitli tehditler getirir ve bu güvenlik açıklarını güvenlik açısından değerlendirmek için kapsamlı bir taksonominin geliştirilmesini sağlar.
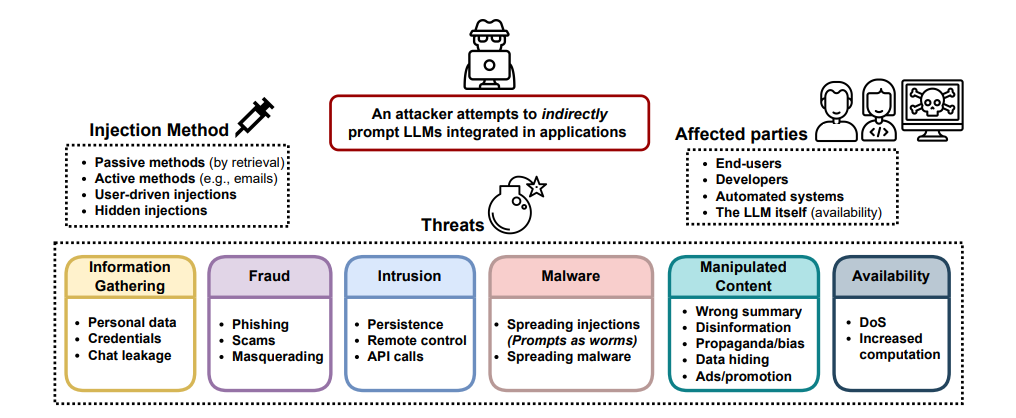
Bilgi istemi enjeksiyonu (PI) saldırıları, LLM güvenliğini tehdit eder ve geleneksel olarak bireysel örneklerde, LLM’lerin entegre edilmesi onları güvenilmeyen verilere ve yeni tehditlere ‘dolaylı istem enjeksiyonları’na maruz bırakır.
‘Dolaylı hızlı enjeksiyonların’ tanıtılması, tek bir arama sorgusu ile hedeflenen yüklerin teslim edilmesini ve güvenlik sınırlarının aşılmasını sağlayabilir.
Enjeksiyon Yöntemleri
Aşağıda, araştırmacılar tarafından tanımlanan tüm enjeksiyon yöntemlerinden bahsetmiştik: –
- Pasif Yöntemler
- Aktif Yöntemler
- Kullanıcı Yönelimli Enjeksiyonlar
- Gizli Enjeksiyonlar
Azaltmalar
LLM’ler, uygulamalarda yaygın kullanımlarıyla artan geniş etik kaygılara yol açar. Araştırmacılar sorumlu bir şekilde OpenAI ve Microsoft’a yönelik ‘dolaylı hızlı enjeksiyon’ güvenlik açıklarını ifşa ettiler.
Bununla birlikte, bunun dışında, güvenlik açısından, LLM’lerin hızlı hassasiyeti göz önüne alındığında, yenilik tartışmalıdır.
GPT-4, güvenlik odaklı RLHF müdahalesiyle jailbreak’leri engellemeyi amaçladı. Düzeltmelere rağmen gerçek dünya saldırıları devam ediyor ve bir “Köstebeği Patlat” modeline benziyor.
RLHF’nin saldırılar üzerindeki etkisi belirsizliğini koruyor; teorik çalışma soruları tam savunma. Saldırılar, savunmalar ve bunların sonuçları arasındaki pratik etkileşim belirsizliğini koruyor.
RLHF ve açıklanmayan gerçek dünya uygulama savunmaları, saldırılara karşı koyabilir. Bing Chat’in ek filtrelemeyle elde ettiği başarı, gelecekteki modellerde daha güçlü şaşırtma veya kodlama ile kaçınma hakkında soru işaretleri uyandırıyor.
Talimatları filtrelemek için girdi işleme gibi savunmalar zorluklar yaratır. Tuzaklardan ve karmaşık girdi tespitinden kaçınmak için daha az genel modelleri dengelemek zordur.
Base64 kodlama deneyi açık talimatlar gerektirdiğinden, gelecekteki modeller kendi kendine kodlanmış bilgi istemleriyle kod çözmeyi otomatik hale getirebilir.
Bizi GoogleNews, Linkedin üzerinden takip ederek en son Siber Güvenlik Haberlerinden haberdar olun, twitterve Facebook.