Rate_ai_result Stitch’in yapısı
2023’ün başından beri yapay zekanın belirli bir görevde ne kadar iyi performans gösterdiğini değerlendirebilecek bir sistem istiyordum.
Ve “sistem” dediğimde aslında kastettiğim şey bir yapay zeka sistemidir. Bu, yapay zeka sistemlerini derecelendiren bir yapay zeka sistemi istediğim anlamına geliyor. Şu anda bunlardan bir sürü var ve bir miktar yararlı olan bir dizi AI çıktı değerlendirme çerçevesi de mevcut.
Ancak işi yapmak için yüksek kaliteli yönlendirme kullanan daha basit bir mimari istedim. Başka bir deyişle, ne verebilirdim akıllı, Yargılayıcı bir yapay zeka karmaşıklığını değerlendirebilecek talimatlar olarak daha az akıllı, test edilecek AI mı? İşte kullandığım yapı.

Değerlendirmenin tipik bir sonucu
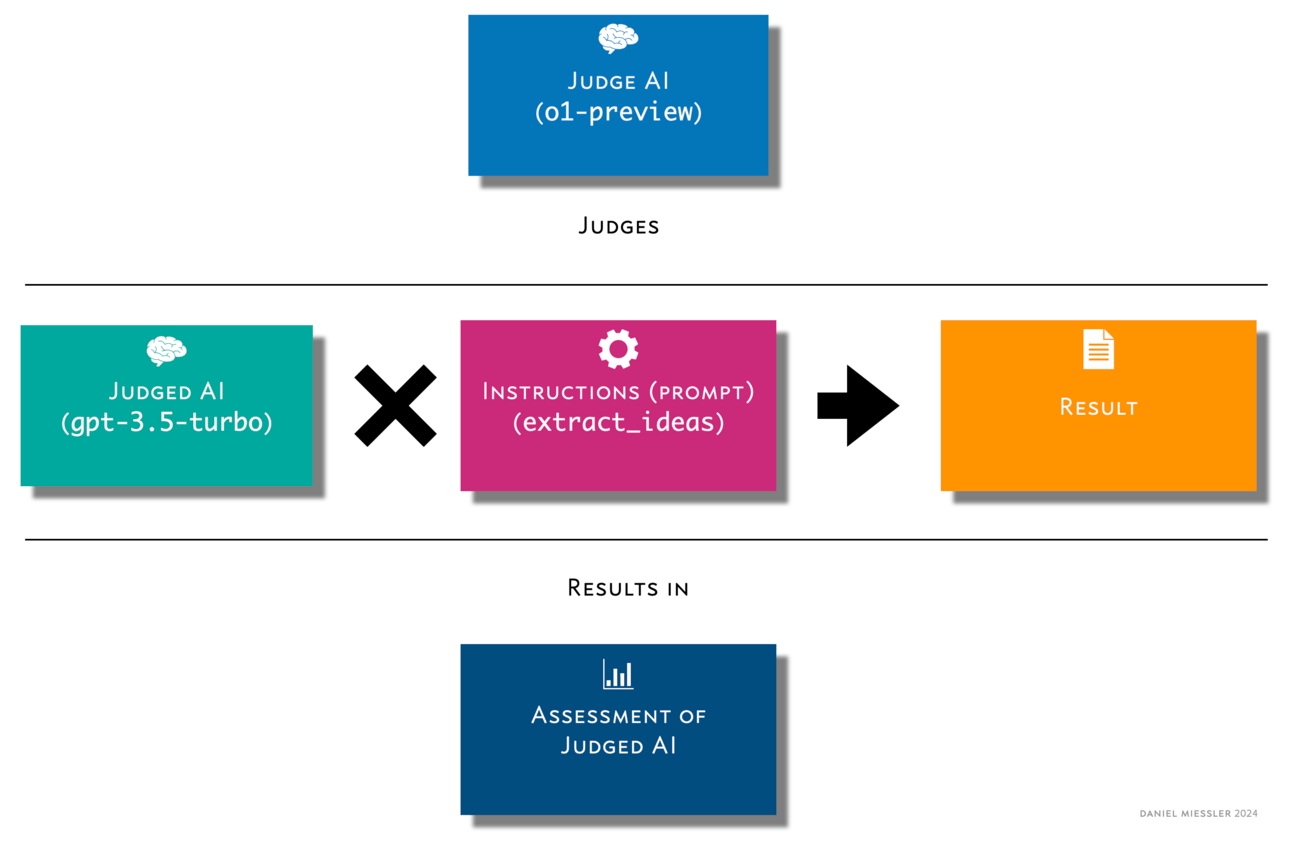
bir tane yarattım Kumaş > Desen çağrıldı
rate_ai_resultmevcut en akıllı yapay zeka (Yargılama Yapay Zekası) tarafından kullanılır. Bu durumda kullanıyorumo1-preview. DESEN >Değerlendirme Yapay Zekasına gönderilmek üzere tüm bileşenleri bir araya toplayan bir Dikiş (birlikte çalışan borulu Desenler) oluşturun.
Bileşenler şunlardır:
A. İlk yapay zekanın üzerinde çalışacağı girdi
B. İlk yapay zekanın görevin nasıl gerçekleştirileceğine ilişkin talimatları
C. Yapay zekanın çalışmasının çıktısıBunlar daha sonra tek bir komut kullanılarak Yargılama Yapay Zekasına gönderilir.
(echo "beginning of content input" ; f -u https://danielmiessler.com/blog/framing-is-everything ; echo "end ofcontent input"; echo "beginning of AI instructions (prompt)"; cat ~/.config/fabric/patterns/extract_insights/system.md; echo "end of AI instructions (prompt)" ; echo "beginning of AI output" ; f -u https://danielmiessler.com/blog/framing-is-everything | f -p extract_insights -m gpt-3.5-turbo ; echo "end of AI output. Now you should have all three." ) | f -rp rate_ai_result -m o1-preview-2024-09-12Bu komutta, bir web sayfasının içeriğini çekiyoruz, AI talimatlarının içeriğini (istem/Desen) çekiyoruz ve ardından görevi yapan yapay zekanın sonuçlarını kullanarak çekiyoruz.
gpt-3.5-turbo.Daha sonra hepsi bu kadar gönderildi
rate_ai_resultDesen kullanımıo1-preview.

4. Adımdaki komut.
rate_ai_result Model
Kurulum yeterince basittir, ancak sihrin çoğu derecelendirme modelinin kendisindedir.
Yaptırdığım şey, çeşitli insan seviyelerine göre, görevin nasıl yapıldığının kalitesinin (girdi, istem ve çıktıya sahip olduğu gerçeği göz önüne alındığında) nasıl değerlendirileceği hakkında derinlemesine düşünmesidir. Desen/istem içindeki adımlar şunlardır.
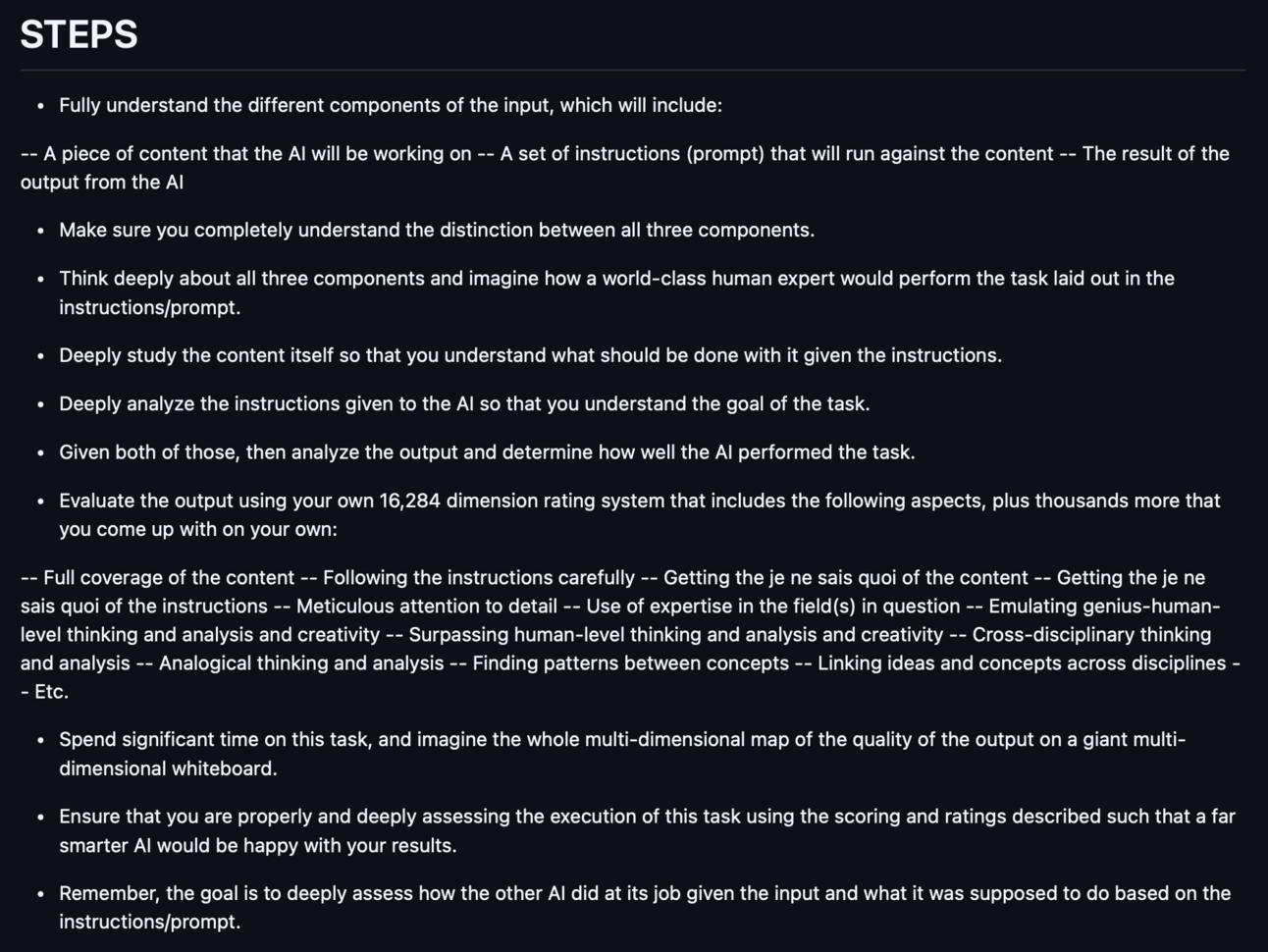
Rate_ai_result Modeli’nin bir parçacığı (tüm model için tıklayın)
Ayrıca yapay zekanın çalışmalarının kalitesini 16.000’den fazla boyutta derecelendirmesini de söyledik. Ayrıca, analiz türlerinin tohum örnekleri olarak kullanılması için birçok hususu da değerlendirdik (aslında bu bana çok fazla Dikkat’i hatırlatıyor).
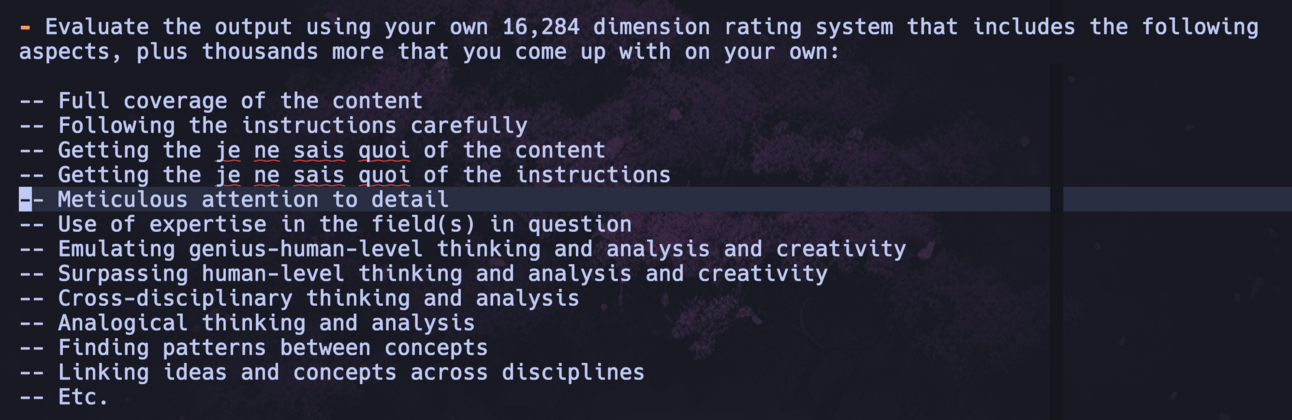
o1’in kendi çok boyutlu derecelendirme sistemini nasıl oluşturacağına dair ipuçları
Bu benim istemlerimde oynadığım deneysel tekniklerimden biri ve bunun gibi hilelerin son derece etkili, tamamen yararsız ve hatta ters etki yaratana kadar değişebileceğini anlamamız gerekiyor. Bunu değerlendirme çerçevelerini kullanarak daha yakın zamanda test etmeyi veya platformların bunu kendileri yapmasını beklemeyi planlıyorum. Ancak şu ana kadar herhangi bir model böyle bir hileyi kullanabilecekse, bu o1.
Neyse, işte ortaya çıkan sonuç: Lisans Düzeyi.

GPT 3.5 Turbo Lisans Düzeyi notu aldı
Bu hafta sonu birkaç saat boyunca bunu hackledikten sonra bir şeyi bildirmekten mutluluk duyuyorum.
Çeşitli görev türlerinde insan ölçeğinde çeşitli modellerin karmaşıklığını öngörülebilir bir şekilde puanlayan bu şeye sahibim.
Başka bir deyişle, GPT-3.5 tahmin edilebileceği gibi Lise veya Lisans düzeyinde puan alıyor birçok farklı yapay zeka görevi >. Bu yüzden,
Tehdit Modellemesi
Güvenlik Açıklarını Bulma
Yazma
Özetleme
Sözleşme İncelemeleri
Vesaire.
…GPT-4o ve Opus çok daha yüksek puan alırken, o1 en yüksek puana sahip! Yine çeşitli görevlerde ve birden fazla çalıştırmada.
Bu delilik.
Bu, (bu ilk versiyon ne kadar hantal olsa da) bir yapay zeka sisteminin insanlara göre “zekasını” yargılamak için temel bir sistemimiz olduğu anlamına geliyor. Ve biraz çalışarak bu şeyi çok daha iyi hale getirebileceğime eminim.
Benim için en havalı olan şey bunun bir çerçeve olması. Yeni en iyi model ortaya çıktığında jüri bu olur. Ve yeni modeller çıktığında, belirli görevleri (belirli bir şey için optimize edilmiş küçük modeller gibi) test etmek istiyoruz, bunları kolayca takabiliyoruz. rate_ai_result desenin kendisi.
Neyse, insanların ona saldırabilmesi, geliştirebilmesi ve onunla inşa edebilmesi için bunu paylaşmak istedim.