Deepseek gibi büyük dil modelleri (LLM’ler) için eğitim verilerinin temel taşı olan ortak tarama veri kümesinin kapsamlı bir analizi – 11.908 canlı API anahtarını, şifreleri ve herkese açık erişilebilir web sayfalarına gömülü kimlik bilgilerini ortaya çıkardı.
AWS’den Slack ve MailChimp’e kadar uzanan hizmetlerle başarılı bir şekilde doğrulanan sızdırılmış sırlar, modeller yanlışlıkla güvensiz kodlama uygulamalarını maruz kalan verilerden öğrendikçe AI geliştirme boru hatlarındaki sistemik riskleri vurgulamaktadır.
Truffle Security’deki araştırmacılar, Aralık 2024 Common Crawl anlık görüntüsünde arşivlenen 2,76 milyon web sayfasında yaygın kimlik bilgisi sabit kodlamaya yönelik temel nedenleri izlediler ve AI tarafından üretilen kod için önlemler hakkında acil sorular sordu.
Deepseek eğitim verilerinin anatomisi
2,67 milyar sayfadan kazınan 400 terabaytlık bir depo olan Common Crawl veri seti, Deepseek ve diğer önde gelen LLM’ler için temel eğitim materyali olarak hizmet vermektedir.
Truffle Security bu cesedi açık kaynaklı trüf aracını kullanarak taradığında, sadece binlerce geçerli kimlik bilgisi değil, rahatsız edici yeniden kullanım kalıplarını keşfetti.

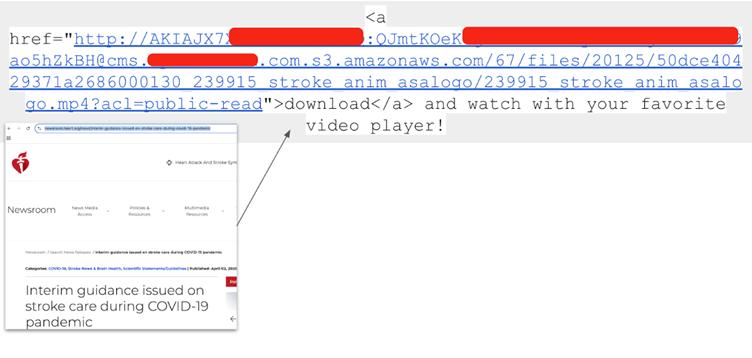
Örneğin, tek bir Walkscore API anahtarı 1.871 alt alanda 57.029 kez görünürken, bir web sayfası ön uç JavaScript’e sabit kodlanmış 17 benzersiz gevşek web şeridi içeriyordu.
MailChimp API tuşları, potansiyel kimlik avı kampanyaları ve veri hırsızlığı sağlayan 1.500 benzersiz anahtarla sızıntıya hakim oldu.
Ölçekte Altyapı: 90.000 Web Arşivi Taraması
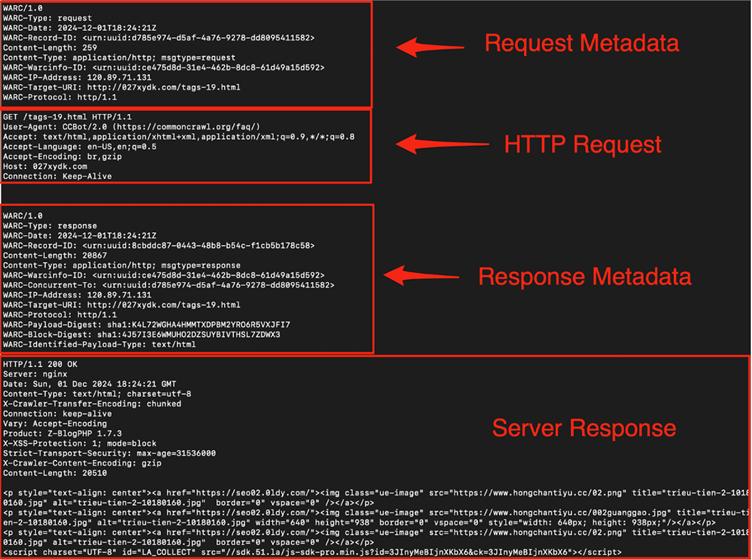
Common Crawl’ın 90.000 WARC (Web Arşivi) dosyasını işlemek için Truffle Security, 20 yüksek performanslı sunucuya dağıtılmış bir sistem kullandı.
Her düğüm 4GB sıkıştırılmış dosyaları indirdi, bireysel web kayıtlarına ayırdı ve canlı sırları algılamak ve doğrulamak için Trufflehog’u çalıştırdı.
Gerçek dünya risklerini ölçmek için, ekip doğrulanmış kimlik bilgilerine öncelik verdi-kendi hizmetleriyle aktif olarak kimlik doğrulaması yapılan taylar.
Özellikle, sırların% 63’ü birden fazla alanda yeniden kullanıldı ve bu da ihlal potansiyelini artırdı.
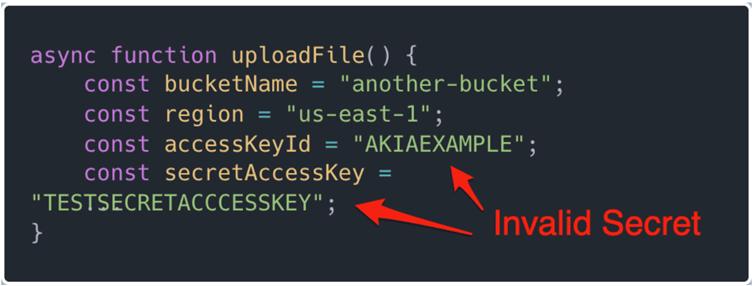
Bu teknik başarı, S3 temel kimlik doğrulaması için ön uç HTML’ye gömülü bir AWS kök anahtarı gibi şaşırtıcı durumları ortaya çıkardı-işlevsel fayda ancak ciddi güvenlik sonuçları olmayan bir uygulama.
Araştırmacılar ayrıca, müşteri sitelerinde API anahtarlarını geri dönüştüren yazılım firmalarını yanlışlıkla ortaya koydu.
Deepseek gibi llms neden tehdidi artırıyor
Common Crawl’ın verileri daha geniş İnternet güvenlik arızalarını yansıtırken, bu örnekleri LLM eğitim setlerine entegre etmek bir geri bildirim döngüsü oluşturur.
Modeller, eğitim sırasında canlı anahtarlar ve yer tutucu örnekleri arasında ayrım yapamaz ve kimlik bilgisi sabit kodlama gibi güvensiz kalıpları normalleştirir.
Bu sorun geçen ay, araştırmacıların LLMS’nin tekrar tekrar geliştiricilere sırları doğrudan koda yerleştirmelerini öğrettikleri dikkat çekti – bu da kusurlu eğitim örneklerine izlenebilir bir uygulama.
AI tarafından üretilen koddaki doğrulama boşluğu
Truffle Security’nin bulguları kritik bir kör noktanın altını çiziyor: Tespit edilen sırların% 99’u geçersiz olsa bile, eğitim verilerinin hacmi LLM çıktılarını güvensiz önerilere yöneltiyor.
Örneğin, binlerce ön uç MailChimp API anahtarlarına maruz kalan bir model, arka uç ortam değişkenlerini göz ardı ederek güvenlik üzerindeki kolaylığa öncelik verebilir.
Bu sorun, kamu kodu depolarından ve web içeriğinden türetilen tüm büyük LLM eğitim veri kümelerinde devam etmektedir.
Endüstri yanıtları ve azaltma stratejileri
Yanıt olarak, Truffle Security çok katmanlı önlemler için savunucular. Yapay zeka kodlama asistanları kullanan geliştiriciler, LLM istemlerine güvenlik korkuluklarını enjekte etmek için Copilot talimatlarını veya imleç kurallarını uygulayabilir.
Örneğin, bir kural belirleyen “Asla sert kodlanmış kimlik bilgilerini önerme önermek” Modelleri güvenli alternatiflere doğru yönlendirir.
Endüstri düzeyinde, araştırmacılar anayasal yapay zeka gibi etik kısıtlamaları doğrudan model davranışına yerleştirmek ve zararlı çıktıları azaltmak için teknikler önermektedir.
Bununla birlikte, bu, eğitim verilerini denetlemek ve sağlam redaksiyon boru hatlarını uygulamak için AI geliştiricileri ve siber güvenlik uzmanları arasında işbirliğini gerektirir.
Bu olay proaktif önlemlere duyulan ihtiyacın altını çiziyor:
- Gizli taramayı genişletin Common Crawl ve GitHub gibi genel veri kümelerine.
- AI eğitim boru hatlarını yeniden değerlendirin hassas verileri filtrelemek veya anonimleştirmek için.
- Geliştirici eğitimini geliştirin Güvenli kimlik bilgisi yönetimi.
Deepseek gibi LLM’ler yazılım geliştirmenin ayrılmaz bir parçası haline geldikçe, eğitim ekosistemlerini güvence altına almak isteğe bağlı değildir – bu varoluşsaldır.
12.000 sızdırılan anahtar sadece daha derin bir rahatsızlığın belirtisidir: yarının yapay zekasını şekillendiren verileri sterilize etmede kolektif başarısızlığımız.
Collect Threat Intelligence on the Latest Malware and Phishing Attacks with ANY.RUN TI Lookup -> Try for free