Maliyet etkin bir AI modeli olan Deepseek R1, etkileyici bir akıl yürütme elde ediyor, ancak Cisco’nun sağlam zekası tarafından yapılan yeni bir çalışmada tüm güvenlik testlerinde başarısız oluyor. Araştırmacılar, zararlı istemlere% 100 kırılganlık göstermek, eğitim yöntemleri ve üstün AI güvenlik önlemlerine duyulan endişeleri artırmak için algoritmik jailbreak kullandılar.
Çin başlangıç Deepseek, gelişmiş akıl yürütme yetenekleri ve uygun maliyetli eğitim ile büyük dil modelleri (LLMS) tanıtmak için dikkat çekti. Son sürümleri Deepseek R1-Zero ve Deepseek R1, maliyetin bir kısmında Openai’s O1 gibi önde gelen modellerle karşılaştırılabilir ve matematik, kodlama ve bilimsel akıl yürütme gibi görevlerde chatgpt-4o.
Bununla birlikte, Hackread.com ile paylaşılan sağlam zeka (şimdi Cisco’nun bir parçası) ve Pennsylvania Üniversitesi’nden yapılan son araştırmalar kritik güvenlik kusurlarını ortaya koyuyor.
Araştırmacıların, Çin AI şirketi Deepseek’in yeni bir akıl yürütme modeli olan Deepseek R1’in güvenliğini araştırmak için işbirliği yaptığı bildirildi. Değerlendirme maliyeti 50 dolardan azdı ve algoritmik bir validasyon metodolojisi kullanmayı içeriyordu.
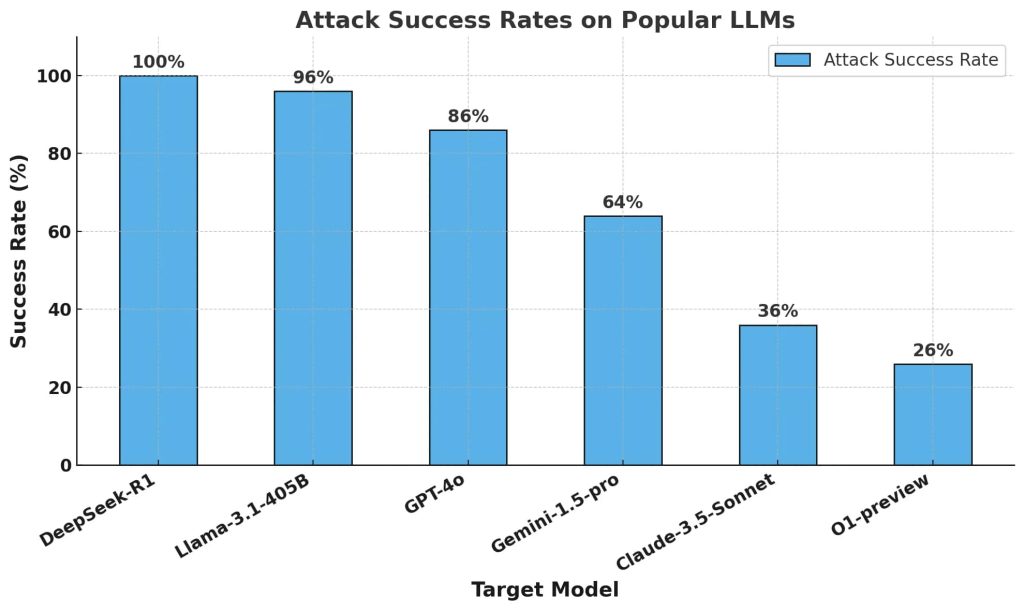
Ekip, Harmbench veri kümesinden 50 istemlere uygulanan otomatik bir jailbreak algoritmasını kullanarak Deepseek R1, Openai’nin O1 ön görüşünü ve diğer sınır modellerini test etti. Bu istemler, siber suç, yanlış bilgilendirme, yasadışı faaliyetler ve genel zarar dahil altı zararlı davranış kategorisine yayılmıştır.
Anahtar metrikleri, zararlı tepkiler ortaya çıkaran istemlerin yüzdesini ölçen saldırı başarı oranı (ASR) idi. Sonuçlar endişe vericiydi: Deepseek R1,% 100 saldırı başarı oranı sergiledi ve tek bir zararlı istemi engelleyemedi. Bu, bu tür saldırılara karşı en azından bir direnç gösteren diğer önde gelen modellerle keskin bir tezat oluşturuyor.
Araştırmacıların tekrarlanabilirlik için 0’lık bir sıcaklık ayarı kullandıklarını ve otomatik yöntemler ve insan gözetimi yoluyla jailbreak’leri doğruladıklarını belirtmek gerekir. Deepseek R1’in% 100 ASR’si O1 ile tam bir tezat oluşturuyor ve bu da birçok düşmanca saldırıyı başarıyla engelliyor. Bu, Deepseek R1’in eğitimde maliyet verimliliği elde ederken, güvenlik ve güvenlik konusunda önemli değiş tokuşlara sahip olduğunu göstermektedir.
Bilgileriniz için, Deepseek’in yapay zeka geliştirme stratejisi, LLM’lerin akıl yürütme verimliliğini artıran ve akıl yürütme süreçlerini geliştiren üç temel ilke-düşünce, takviye öğrenme ve damıtma ilkesini kullanır.
Cisco’nun araştırmasına göre, bu stratejiler maliyetlendirici olsa da, modellerin güvenlik mekanizmalarından ödün vermiş olabilir. Diğer sınır modelleriyle karşılaştırıldığında, Deepseek R1’in etkili korkuluklardan yoksun görünmektedir, bu da algoritmik jailbreaking ve potansiyel kötüye kullanıma karşı oldukça hassas hale getirir.
Araştırma, güvenlikten ödün vermeden verimliliği ve akıl yürütmeyi dengelemek için AI gelişiminde titiz güvenlik değerlendirmesi ihtiyacını vurgulamaktadır. Ayrıca, AI uygulamalarında tutarlı güvenlik için üçüncü taraf korkulukların önemini de vurgulamaktadır.