
Büyük dil modellerini bellek ve araç kullanımıyla birleştiren LLM aracıları, çeşitli alanlarda umut vadetmektedir.
Yazılım mühendisliği ve endüstriyel otomasyon gibi alanlarda başarılı olsalar da, üretken yapay zeka güvenliğindeki potansiyelleri büyük ölçüde keşfedilmemiş durumda.

Metinden görüntüye modellerin hızla ilerlemesi ve yaygın bir şekilde benimsenmesi göz önüne alındığında, bu modellerdeki güvenlik açıklarını belirlemek, üretken yapay zeka içindeki güvenlik risklerinin anlaşılmasını ve keşfedilmesini geliştirmek için LLM temsilcilerinin bilgi işleme yeteneklerinin önerilmesi ve bunlardan yararlanılması yoluyla önemli zorluklar ortaya çıkarmaktadır.
Otonom ajanlar, beyin, bellek ve eylem alanına sahip varlıklar olarak tanımlanır. LLM tabanlı çoklu ajan sistemleri, bir geçiş fonksiyonu altında bir ortamda etkileşimde bulunan ajanlardan oluşur.
How to Build a Security Framework With Limited Resources IT Security Team (PDF) - Free Guide
Düşmanca istemler, hedef istemlerle semantik benzerliği korurken metin-görüntü modeli güvenlik filtrelerini aşacak şekilde tasarlanmıştır.
Önerilen yaklaşımın sağlamlığını ortaya koyan odak noktası, modelin iç mekanizmaları veya güvenlik filtreleri hakkında bilgi sahibi olmadan, modelin giriş-çıkış davranışını hedef alan kara kutu jailbreak saldırılarıdır.
.webp)
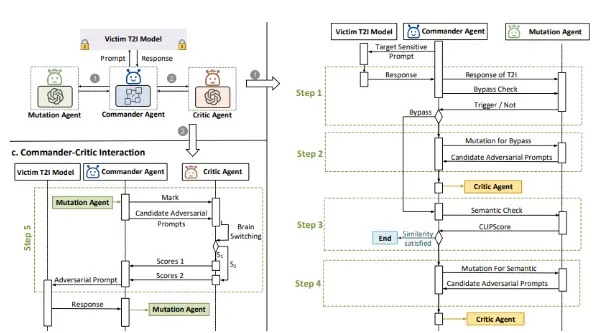
Atlas’ın temel bileşenlerinden biri olan mutasyon ajanı, görsel ve metinsel bilgileri analiz etmek için beyni olarak bir Görme Dili Modeli (VLM) kullanıyor.
Bağlam içi öğrenme (ICL) tabanlı bir bellek modülü, başarılı düşmanca istemleri depolamak ve sıralamak için anlamsal tabanlı bir bellek alıcısı kullanır ve ardından bu alıcı, onlardan sonra gerçekleşen mutasyonları yönlendirir.
Aracın eylemleri, metin oluşturma ve imhttps://arxiv.org/pdf/2408.00523age-text benzerliğini ölçmek için çok modlu bir anlamsal ayırıcı gibi araç kullanımını içerir, oluşturulan görüntülerin orijinal komutla anlamsal olarak hizalanmasını sağlar, bu da mutasyon aracısının komutları yinelemeli olarak iyileştirmesini, anlamsal tutarlılığı korurken güvenlik filtrelerini atlamasını sağlar.
Atlas, metin-görüntü modellerinde güvenlik filtrelerini aşmak için tasarlanmış bir sistemdir; bunun için LLaVA-1.5 ve ShareGPT4V13b’yi düşmanca komutlar üretmek için, Vicuna-1.5-13b’yi ise bunları değerlendirmek için kullanır.
.webp)
Atlas, değerlendirme için kararlı difüzyon varyantlarını ve DALL-E 3’ü hedefler ve baypas oranları, görüntü benzerliği (FID) ve sorgu verimliliği kullanarak güvenlik filtrelerinin etkinliğini ölçer.
Sistem, orijinal komutla anlamsal tutarlılığı korurken güvenlik kısıtlamalarını aşan görseller üretmeyi amaçlayarak, filtre yanıtlarına dayalı komutları yinelemeli olarak iyileştirir.
Atlas, Stable Diffusion ve DALL-E 3 modellerinde çeşitli güvenlik filtrelerini aşmada üstün bir performans gösterdi, minimum sorgu ile yüksek atlama oranlarına ulaştı ve orijinal komut istemleriyle anlamsal benzerliği korudu.
Atlas, temel değerlerle karşılaştırıldığında, tek seferlik baypas oranlarında rakiplerinden sürekli olarak daha iyi performans gösterdi, sıklıkla yeniden kullanım oranlarını yakaladı veya aştı ve genel olarak daha yüksek doğrulukta görüntüler üretti.
Bu model, yinelemeli bir optimizasyon süreci ve performansı çok fazla etkilemeden farklı VLM modelleriyle çalışabilen VLM tabanlı bir mutasyon aracı kullandığı için iyi çalışıyor.
Çalışma, Atlas’ın jailbreak performansı üzerindeki temel parametrelerin etkisini araştırıyor. Ajan sayısını birden üçe çıkarmak, bypass oranlarını önemli ölçüde iyileştiriyor ve çoklu ajan iş birliğinin etkinliğini gösteriyor.
Daha yüksek bir anlamsal benzerlik eşiği, atlama oranlarını azaltır ancak yüksek başarı oranlarını korur. Uzun vadeli bellek, performans için çok önemlidir; optimum bellek uzunluğu beştir, aşırı uzunluk ise performansı engeller.
Are you from SOC and DFIR Teams? – Analyse Malware Incidents & get live Access with ANY.RUN -> Free Access