Antropic, şirketin en gelişmiş modeli ve sevk ettiği ilk hibrit akıl yürütme modeli olan Claude 3.7 Sonnet’i piyasaya sürmeye başladı.
İlk testler, Claude 3.7 Sonnet’in Openai’nin ChatGPT modelleri ve Çin’in Deepseek’i de dahil olmak üzere rakiplerinden daha iyi performans gösterdiğini gösteriyor.
Bir blog yazısında Antropic, en yeni modelinin hızlı, basit cevapları karmaşık görevler için adım adım “düşünme” ile birleştirdiğini belirtti. Bu, Claude 3.7 modelini programlama için en iyisi haline getirir ve bu iddialar kriterlerle desteklenir.
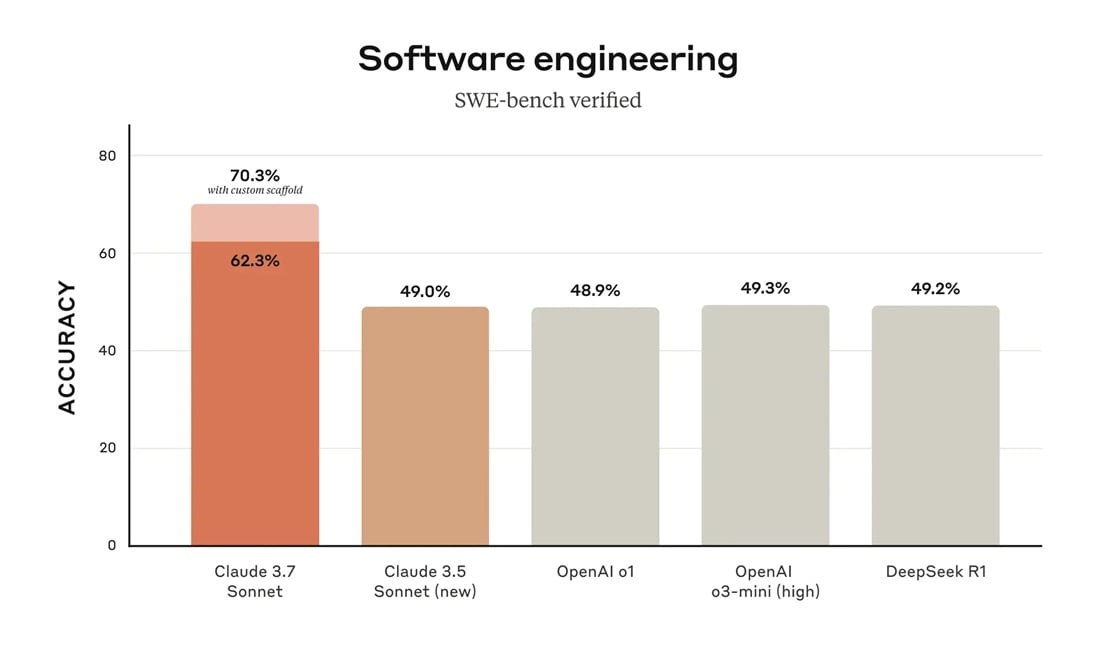
“Yazılım Mühendisliği (SWE-Bench doğrulandı)” adlı bir kıyaslama testine göre, Claude 3.7 sonnet, ekstra test süresi “iskele” kullanırken% 70’e kadar olan kabaca% 62 doğrulukla zirvede.
Claude 3.5 sonnet ve Openai’nin varyantları da dahil olmak üzere rakip modeller% 50 aralığına daha yakın oturuyor.
“Yazılım Mühendisliği (SWE-Bench doğrulanmış)” bir programı kodlamanız istendiğinde bir AI modelinin ne kadar iyi yaptığını görmek için bir kıyaslama standardıdır.
Bu sonuçlar Claude 3.7 sonnet’in kodlama açısından rakiplerinin önemli ölçüde önünde olduğunu gösteriyor.
Bazı kullanıcılar için AGI anı
Kullanıcılar ayrıca sonuçların deli olduğunu iddia ediyorlar.
Örneğin, bir iş parçacığında, Reddit kullanıcıları, modelin uygulamalar ve hatta oyunlar oluşturmak için kullandıklarında olağanüstü sonuçlar verdiğini belirtti.
“Claude kodu benim ‘AGI anını hissedin’ idi. Başka hiçbir modelin düzeltemeyeceği bu şeyde hatalar attım, ancak Claude kodu onlardan patladı, “bir kullanıcı Reddit iş parçacığında yazdı.
Başka bir kullanıcı ekledi: “3.7 aylardır üzerinde çalıştığım tüm bir projeyi tokatladı-5000 satır kod, ön uç, hata ayıklama örneği, hepsi sıfırdan. İş bitene kadar durmadı. ”
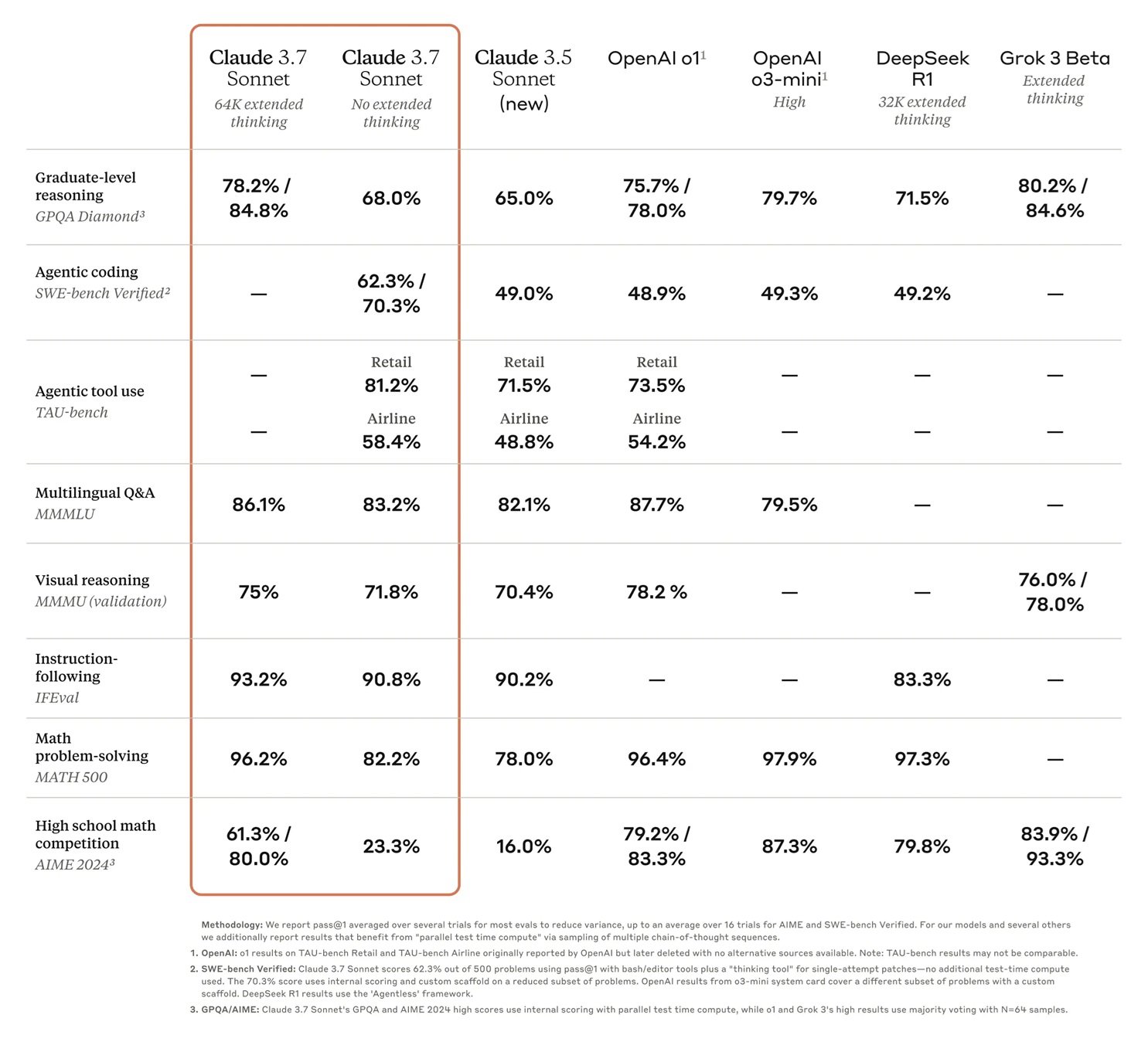
Buna ek olarak, Claude 3.7 sonnet çoğu kategoride mükemmel görünüyor, “genişletilmiş düşünme” modu matematik ve bilim gibi görevler üzerindeki doğruluğu artırıyor.
Openai’nin 0.1 ve Deepseek R1 gibi diğer modeller, bu testlerin çoğunda geride kalıyor.