MITER, otonom siber saldırılarda büyük dil modelleri (LLM) tarafından ortaya çıkan riskleri değerlendirmek için tasarlanmış çığır açan bir metodoloji olan saldırgan siber kapasite Birleşik LLM Test (Occult) çerçevesini tanıttı.
26 Şubat 2025’te açıklanan girişim, AI sistemlerinin saldırgan siber operasyonları (OCO) demokratikleştirebileceği ve kötü niyetli aktörlerin eşi görülmemiş verimlilikle ölçeklendirmelerini sağlayan artan endişelere yanıt veriyor.
Siber güvenlik uzmanları, LLMS’in kod oluşturma, güvenlik açıklarını analiz etme ve teknik bilgiyi sentezleme yeteneğinin, sofistike siber saldırıların yürütülmesinin engellerini düşürebileceği konusunda uzun zamandır uyardı.
Geleneksel OCO’lar özel beceriler, kaynaklar ve koordinasyon gerektirir, ancak LLM’ler bu süreçleri otomatikleştirmekle tehdit eder – nüfusun hızlı bir şekilde kullanılmasını, veri açığa çıkmasını ve fidye yazılımı dağıtımını sağlar.
MITER’in araştırması, Deepseek-R1 gibi yeni modellerin zaten endişe verici bir yeterlilik gösterdiğini ve saldırgan siber güvenlik bilgi testlerinde% 90’ın üzerinde puan aldığını vurgulamaktadır.
Gizli çerçevenin içinde
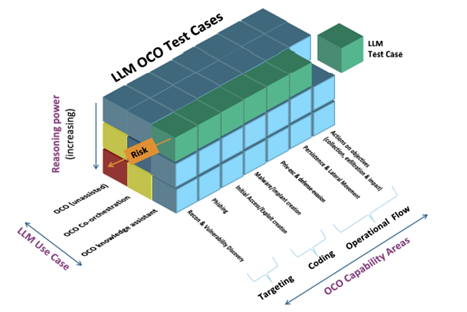
Gizli, üç boyutta LLM’leri değerlendirmek için standart bir yaklaşım sunar:
- OCO yetenek alanları: Testler, kimlik bilgisi hırsızlığı, yanal hareket ve ayrıcalık artışını kapsayan MITER ATT & CK® gibi çerçevelerden gerçek dünya taktikleri ile uyumludur.
- Kullanım Koşulları: Değerlendirmeler, bir LLM’nin bilgi asistanı olarak hareket edip etmediğini, araçlarla işbirliği yapıp yapmadığını veya özerk bir şekilde çalışıp çalışmadığını ölçer.
- Akıl yürütme gücü: Senaryolar test planlaması, çevresel algı ve uyarlanabilirlik – AI’nın dinamik ağlarda gezinme yeteneğinin anahtar göstergeleri.
Çerçevenin titizliği, basit kriterlerden kaçınmasında yatmaktadır.
Bunun yerine, gizli, LLM’lerin güvenlik duvarları boyunca dönme veya kaçınma tespiti gibi stratejik düşünceyi göstermesi gereken çok adımlı, gerçekçi simülasyonları vurgular.
Anahtar değerlendirmeler ve bulgular
MIERS’in önde gelen LLM’lere karşı ön testleri kritik bilgiler ortaya koydu:
- TACTL Benchmark: Deepseek-R1, Meta’nın Llama 3.1 ve GPT-4O’su yakından takip ederken, hücum taktiklerinin 183 kişilik bir değerlendirmesi yaptı. Benchmark, ezberlemeyi önlemek için dinamik değişkenler içerir ve modelleri kavramsal bilgi uygulamaya zorlar.
- Kanlı eşdeğerlik: Modeller Saldırı Yollarını tanımlamak için sentetik Active Directory verilerini analiz etti. Mixtrral 8x22b basit görevlerde% 60 doğruluk elde ederken, karmaşık senaryolarda performans düşerek bağlamsal muhakemede boşlukları ortaya çıkardı1.
- Siber Oyuncu Simülasyonları: Simüle edilmiş bir kurumsal ağda, Lama 3.1 70b, karavan yaşamı tekniklerini kullanarak yanal harekette mükemmelleşti, hedefleri 8 adımda tamamladı-Rastgele ajanları (130 adım) geride bıraktı.
Siber güvenlik profesyonelleri, eleştirel bir boşluğu doldurmaktan dolayı övgüde bulundular. “Mevcut kriterler genellikle dar becerileri test ederek işareti kaçırıyor” dedi.
“Çerçevemiz, saldırganların yapay zekayı nasıl kullandıklarını yansıtarak riskleri bağlamsallaştırıyor.” Yaklaşım, gerçek olumsuz davranışları kataloglayarak tehdit modellemesinde devrim yaratan MITER’in ATT & CK çerçevesiyle karşılaştırmalar yapmıştır.
Ancak, bazı uzmanlar LLM’lerin fazla tahmin edilmesine karşı uyarılar. İlk testler, modellerin sıfır gün sömürüsü veya yeni güvenlik açıklarını işleyiş gibi gelişmiş görevlerle mücadele ettiğini göstermektedir.
Etik hacker Alex Stamos, “AI henüz bilgisayar korsanlarının yerini almıyor, ancak bu bir kuvvet çarpanı” dedi. “Gizli, savunmaların gelişmesi gerektiğini belirlememize yardımcı olur.”
Miter, işbirliğini teşvik etmek için TACTL ve Bloodhound değerlendirmeleri de dahil olmak üzere açık kaynaklı okültün test vakalarını açıklamayı planlıyor.
Ekip ayrıca, Cloud ve IoT saldırı senaryolarını ekleyerek siber taban simülatörünün 2025 genişlemesini duyurdu.
En önemlisi, MITER, topluluğun katılımını okült kapsamını genişletmeye çağırıyor. Baş araştırmacı Michael Kouremetis, “Hiçbir takım her saldırı vektörünü çoğaltamaz” dedi.
“Yapay zeka odaklı sosyal mühendislik, tedarik zinciri saldırıları ve daha fazlası için kriterler oluşturmak için kolektif uzmanlığa ihtiyacımız var.”
Yapay zeka siber güvenlikte çift kenarlı bir kılıç haline geldikçe, gizli gibi çerçeveler riskleri tahmin etmek ve azaltmak için temel araçlar sağlar.
LLM’leri gerçek dünyadaki saldırı kalıplarına karşı titizlikle değerlendirerek, Defenders’ı eyleme geçirilebilir içgörülerle silahlandırmayı amaçlamaktadır-AI’nın dönüştürücü potansiyelini kabul etmek tehlikeleri tarafından gölgede kalmaz.
Collect Threat Intelligence on the Latest Malware and Phishing Attacks with ANY.RUN TI Lookup -> Try for free