
Cybersoceval adlı çığır açan bir açık kaynaklı kıyaslama paketi, Güvenlik Operasyon Merkezi (SOC) ortamlarında büyük dil modelleri (LLMS) için ilk kapsamlı değerlendirme çerçevesi olarak ortaya çıkmıştır.
Cyberseceval 4’ün bir parçası olarak yayınlanan bu yenilikçi ölçüt, iki temel savunma alanına odaklanarak siber güvenlik AI değerlendirmesindeki kritik boşlukları ele almaktadır: kötü amaçlı yazılım analizi ve tehdit istihbarat muhakemesi.
Meta ve Crowdstrike tarafından yürütülen araştırma, mevcut AI sistemlerinin bu güvenlik odaklı değerlendirmeleri doyurmaktan uzak olduğunu ve kötü amaçlı yazılım analiz görevlerinde yaklaşık% 15 ila% 28 ve tehdit istihbarat akıl yürütmesinde% 43 ila% 53 arasında değiştiğini ortaya koymaktadır.

Key Takeaways
1. CyberSOCEval, the first open-source benchmark testing LLMs on Security Operations Center tasks.
2. Current LLMs achieve only 15-28% accuracy on malware analysis and 43-53% on threat intelligence.
3. 609 malware questions and 588 threat intelligence questions evaluate AI systems on JSON logs, MITRE ATT&CK mappings, and complex attack chains.
Bu sonuçlar AI siber savunma yeteneklerinde iyileşme için önemli fırsatları vurgulamaktadır.
Cybersoceval kötü amaçlı yazılım analizi
Cybersoceval’in kötü amaçlı yazılım analiz bileşeni, Crowdstrike Falcon® Sandbox’tan gerçek kum havuzu patlama verilerini kullanır ve fidye yazılımı, uzaktan erişim truva atları (sıçanlar), infostenerler, EDR/AV öldürücüler ve UM okşama teknikleri dahil olmak üzere beş kötü amaçlı yazılım kategorisinde 609 soru cevap çifti oluşturur.
Benchmark, AI sistemlerinin karmaşık JSON biçimlendirilmiş sistem günlüklerini, işlem ağaçlarını, ağ trafiğini ve MITER ATT & CK çerçeve eşlemelerini yorumlama yeteneğini değerlendirir.
Teknik özellikler, performans bütünlüğünü korurken rapor boyutunu azaltan filtreleme mekanizmalarıyla 128.000’e kadar jeton bağlam penceresine sahip modellere destek içerir.
Değerlendirme, T1055.001 (proses enjeksiyonu), T1112 (kayıt defteri çalıştırma anahtarları) ve Createmotethread, VirtualAlloc ve WriteProcessMemory gibi API çağrıları dahil kritik siber güvenlik kavramlarını kapsar.
Tehdit İstihbaratı Akıl Yürütme Karşılaştırma İşlemleri Crowdstrike, CISA, NSA ve IC3’ten kaynaklanan 45 farklı tehdit istihbarat raporundan türetilen 588 soru-cevap çiftleri.
CTibench ve Sevenllm gibi mevcut çerçevelerin aksine, Cybersoceval, uzlaşma metin göstergelerini (IOC) tablolar ve diyagramlarla birleştiren multimodal zeka raporlarını içeriyor.
Değerlendirme metodolojisi, LLAMA 3.2 90B ve Lama 4 Maverick modellerini kullanarak hem kategoriye dayalı hem de ilişkiye dayalı soru üretimi kullanır.
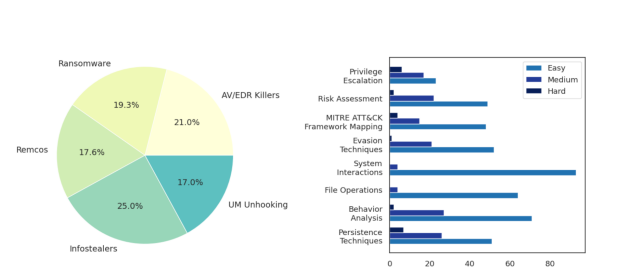
Kötü Yazılım Saldırısı ve Konu ve Zorluğa Göre Dağıtımla Patlama Raporu Dağıtım
Sorular, Tehdit Oyuncusu ilişkileri, kötü amaçlı yazılım ilişkilendirmesi ve MITER ATT & CK gibi çerçevelere eşlenmiş karmaşık saldırı zinciri analizi arasında çok hızlı akıl yürütmeyi gerektirir.
Meta, test süresi ölçeklendirmesinden yararlanan akıl yürütme modellerinin, kodlama ve matematik alanlarında gözlenen performans iyileştirmelerini göstermediğini ve siber güvenliğe özgü akıl yürütme eğitiminin önemli bir geliştirme fırsatını temsil ettiğini göstermediğini söyledi.
Benchmark’ın açık kaynaklı doğası, topluluk katkılarını teşvik eder ve uygulayıcılara güvenilir model seçim metrikleri sağlar ve AI geliştiricilerine siber savunma yeteneklerini geliştirmek için net bir geliştirme yol haritası sunar.
Free live webinar on new malware tactics from our analysts! Learn advanced detection techniques -> Register for Free