
Dinamik kötü amaçlı yazılım analizi için kullanılan kaliteli API çağrı dizilerinde karşılaşılan dezavantajların üstesinden gelebilecek, mühendislik destekli yeni bir Dinamik Kötü Amaçlı Yazılım Analizi modeli tanıtıldı.
Bu yeni yöntemin, son teknoloji ürünü TextCNN yöntemini aşan bir algılama gerçekleştirdiği bildirildi. Bu yöntem, dinamik kötü amaçlı yazılım analizi için GPT-4’ü kullanır ve ayrıca metnin temsilini almak için BERT’i (Transformatörlerden Çift Yönlü Kodlayıcı Gösterimleri) kullanır.
GPT-4 kullanarak Dinamik Kötü Amaçlı Yazılım Analizi
Bu yeni yöntem, sıradaki her API çağrısı için açıklama metinleri üretir. Ayrıca, bu yöntemde oluşturulan bilgilendirici metinler, GPT-4’ün yüksek kaliteli açıklayıcı metinler oluşturmasını geliştirir.
Bu açıklayıcı metinler oluşturulduktan sonra BERT, bu metinler için temsiller oluşturur ve bunlar daha sonra tüm API dizisini gösterecek şekilde bir araya getirilir. Daha sonra yeni CNN (Evrişimli Sinir Ağı), otomatik öğrenme için gösterimlerden özellikleri çıkarmak için kullanılır.
Son olarak model, daha fazla analiz için çeşitli kötü amaçlı yazılım kod kategorileriyle ilişkilendirilir.
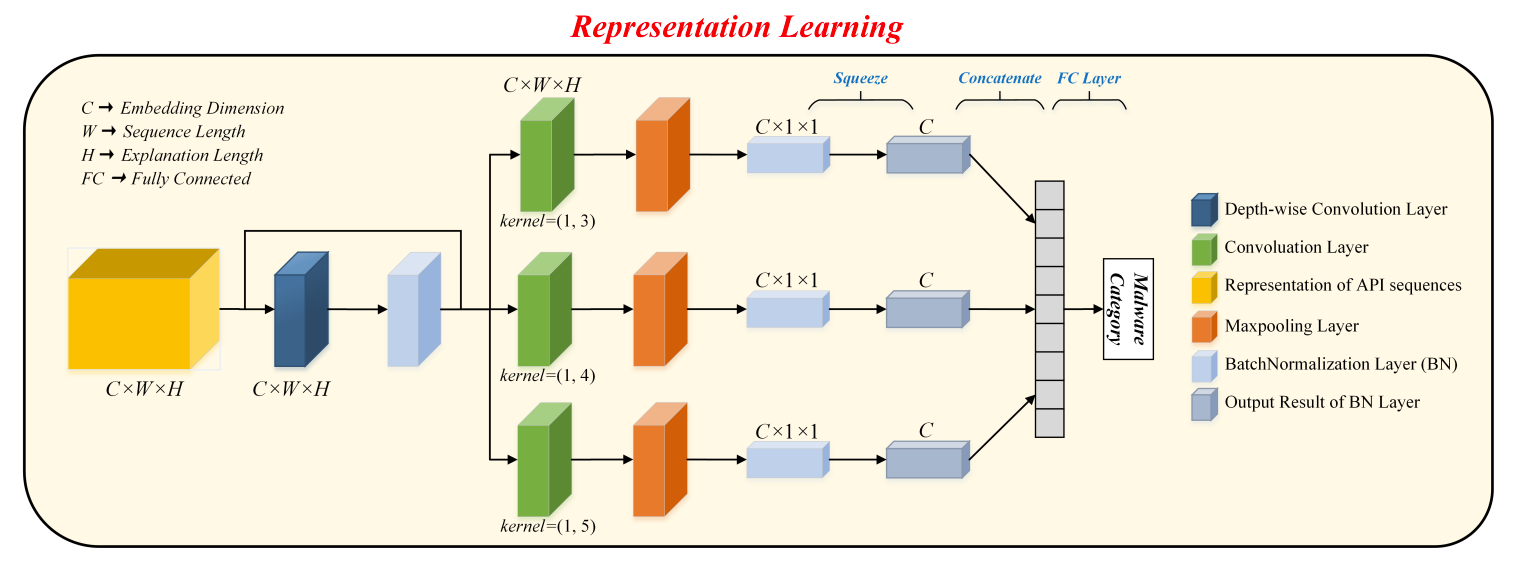
Temsil Üretimi ve Temsil Öğrenme
API dizisinin temsilini oluşturmak için, her API çağrısı için daha sonra temsil oluşturma sürecinde kullanılacak açıklayıcı metni oluşturacak bir sözlük oluşturulur.
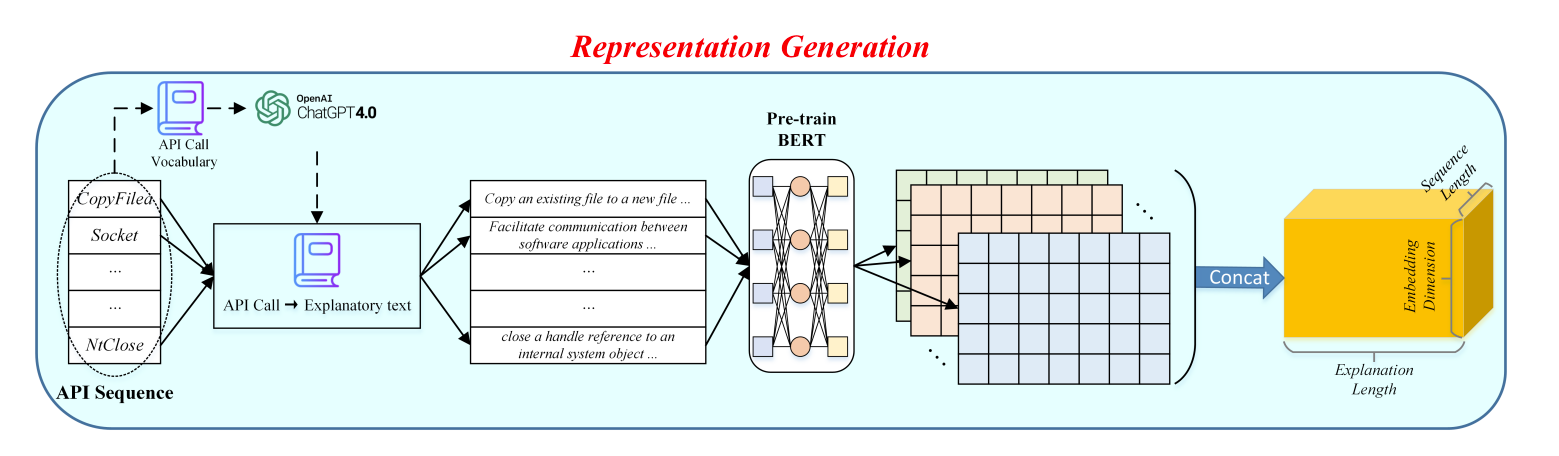
Temsil öğrenimine gelince, derinlemesine bir evrişim gerçekleştirilir. Her gömülü kanal, her biri çevredeki öğeler arasında bağlamsal bir korelasyona sahip olan bir temsil matrisiyle ilişkilendirilir. Eğitilen modül, daha iyi yansıma için doğal metin gösteriminin ayarlanmasını geliştirme kapasitesine sahiptir.
Ayrıca önerilen modelin performansını değerlendirmek için beş kıyaslama veri seti kullanıldı. Bu beş veri kümesi ayrıca ilgili API sözlüğüne göre iki kategoriye ayrıldı.
Araştırma deneyleri, temsil oluşturma, temsil öğrenme, önerilen modellerin grafiği ve diğer bilgiler hakkında ayrıntılı bilgi sağlayan bu deneysel model hakkında tam bir rapor yayınlandı.